import PyPDF2
pdf = path_data + '/' + file
archivo_pdf = open(pdf, 'rb')
pdf_reader = PyPDF2.PdfReader(archivo_pdf)
contenido_pdf = []
words = ['NO', 'TIME', 'P', '']
words += ['TheF', 'FORMULA', 'logo,F', 'logo,FORMULA', ',FORMULAONE,F',
',FIAFORMULAONEWORLDCHAMPIONSHIP,GRANDPRIXandrelatedmarksaretrademarksofFormulaOneLicensingBV,a', 'Formula',
'company.TheFIAlogoisatrademarkoftheFédérationInternationaledel', '’', 'Automobile.Allrightsreserved.',
'Nopartoftheseresults/datamaybereproduced,storedinaretrievalsystemortransmittedinanyformorbyanymeanselectronic,mechanical,photocopying,recording,broadcastingorotherwisewithout',
'priorpermissionofthecopyrightholderexceptforreproductioninlocal/national/internationaldailypressandregularprintedpublicationsonsaletothepublicwithin',
'90', 'daysoftheeventtowhichthe',
'results/datarelateandprovidedthatthecopyrightsymbolandnameofcopyrightownerappears.',
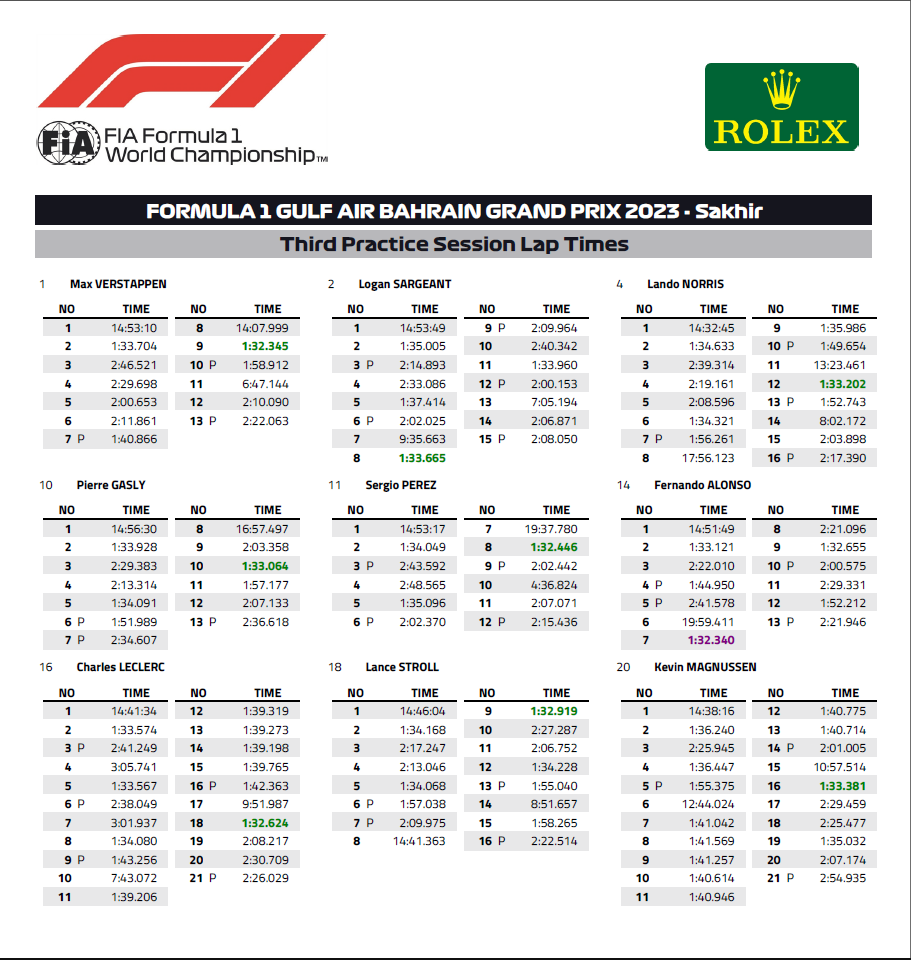
'©2022FormulaOneWorldChampionshipLimited', 'Page3of3', 'FORMULA1GULFAIRBAHRAINGRANDPRIX2022-Sakhir',
'FirstPracticeSessionLapTimes', 'LAP']
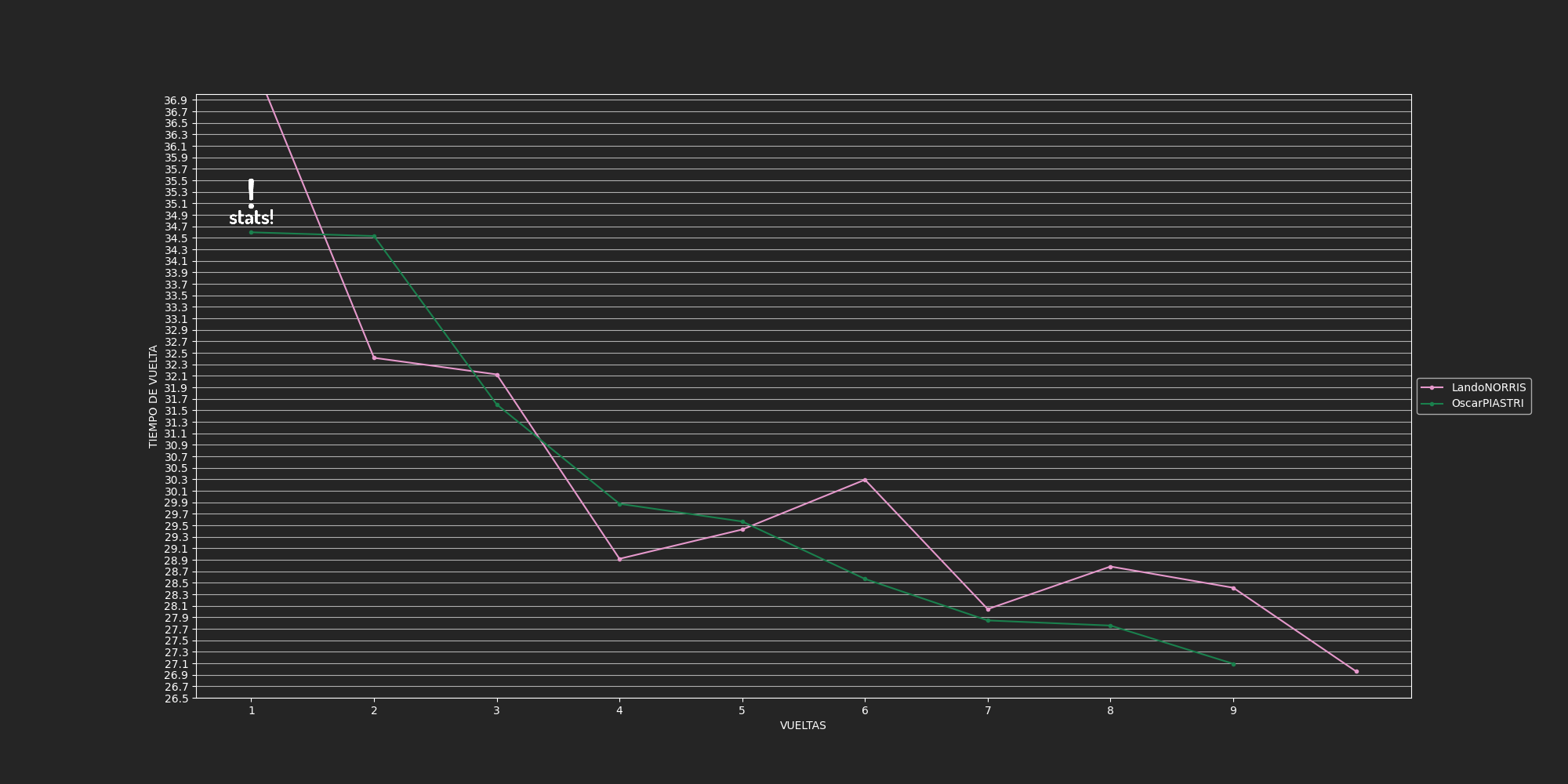
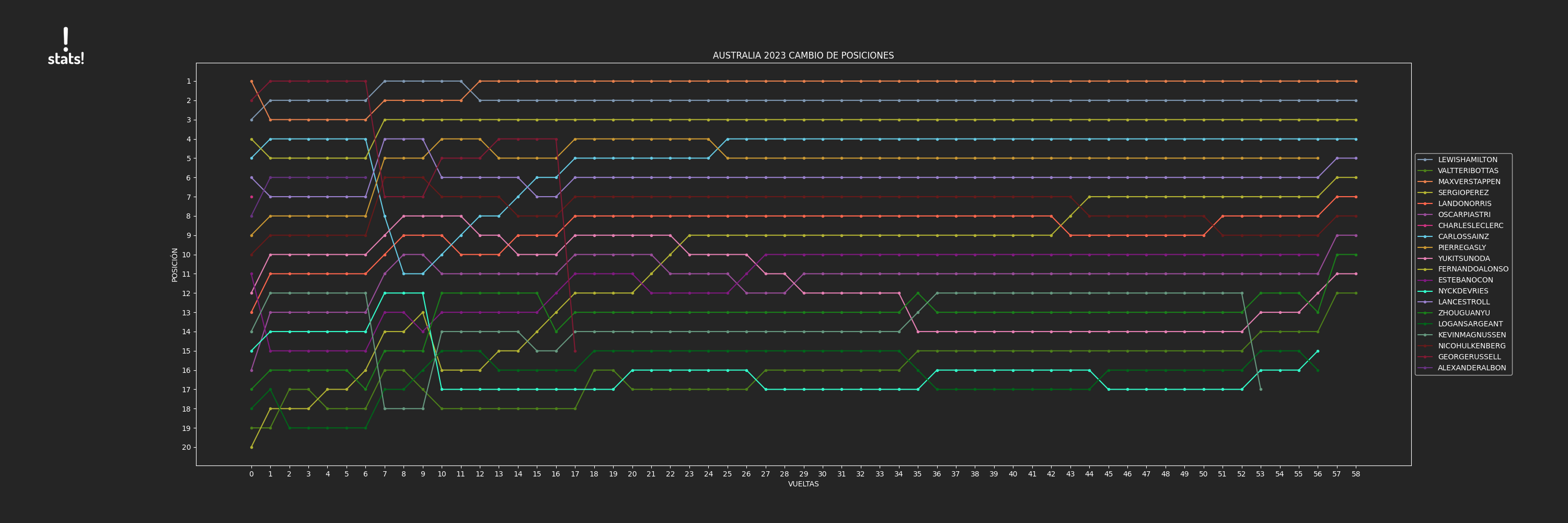
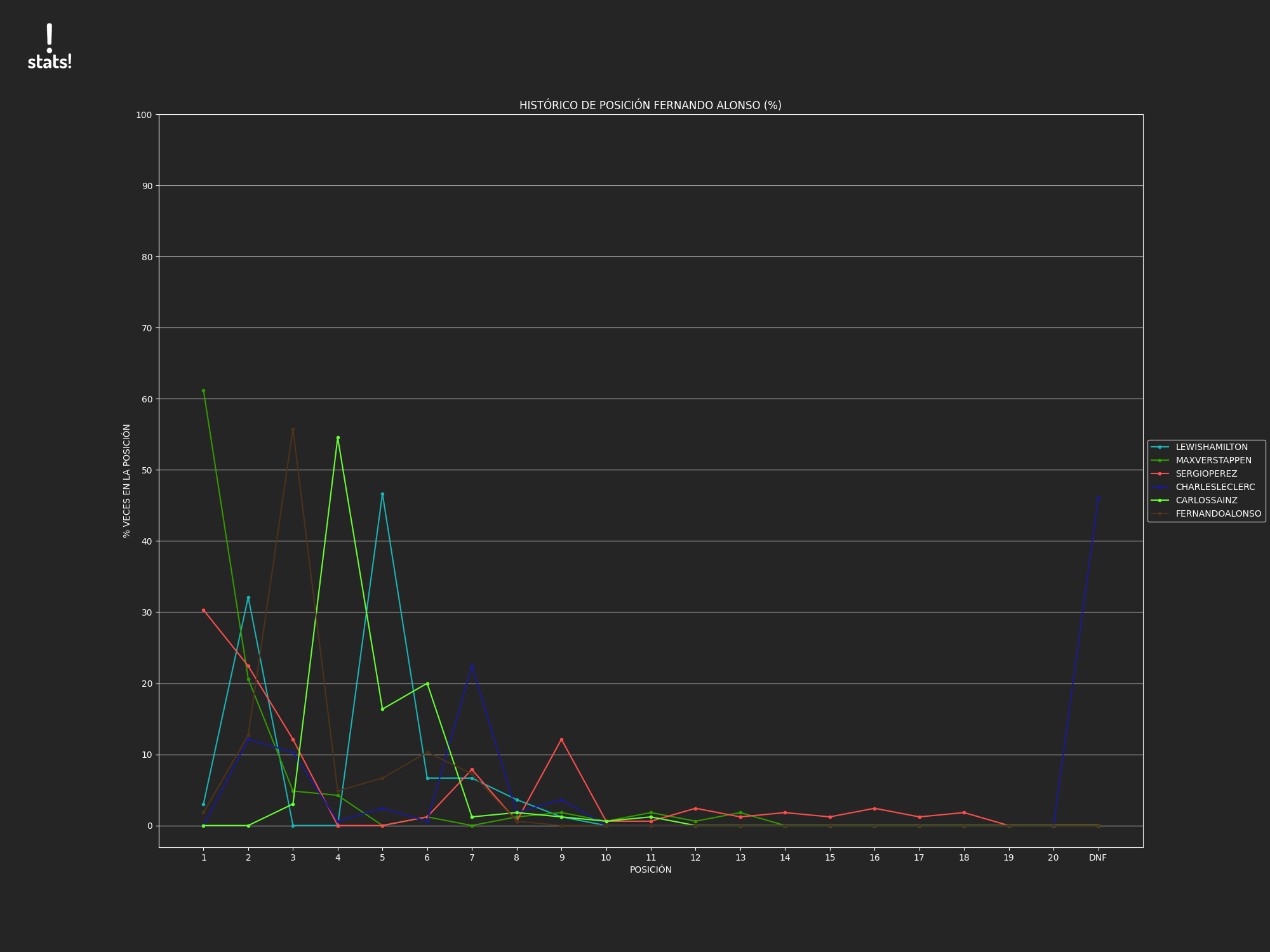
pilots = ['Lewis Hamilton', 'Valtteri Bottas', 'Max Verstappen', 'Sergio Perez', 'Lando Norris', 'Oscar Piastri',
'Charles Leclerc', 'Carlos Sainz', 'Pierre Gasly', 'Yuki Tsunoda', 'Fernando Alonso', 'Esteban Ocon',
'Nyck DE VRIES', 'Lance Stroll', 'ZHOU Guanyu', 'Logan SARGEANT', 'Kevin MAGNUSSEN', 'Nico HULKENBERG',
'George Russell', 'Alexander ALBON']
lap_data = {}
lap_id = []
minimum_laps = []
min_laps_order = []
for i in range(len(pilots)):
pilots[i] = pilots[i].replace(' ', '').upper()
for pagina in range(len(pdf_reader.pages)):
pagina_actual = pdf_reader.pages[pagina]
contenido_pdf.append(pagina_actual.extract_text())
pdf_data = []
for page in contenido_pdf:
line_list = page.split('\n')
data = []
for i in range(len(line_list)):
line_list[i] = line_list[i].replace(' ', '')
for line in line_list:
if line not in words:
data.append(line)
pdf_data += data
for i in range(len(pdf_data)):
if pdf_data[i].upper() in pilots:
lap_data[pdf_data[i]] = {}
lap_id.append(i)
for i in range(len(lap_id)):
start = lap_id[i]
if i < len(lap_id) - 1:
end = lap_id[i + 1]
else:
end = len(pdf_data)
for j in range(start + 1, end, 2):
lap_num = pdf_data[j]
if j < len(pdf_data) - 1:
lap_time = pdf_data[j + 1]
if ':' in lap_time:
lap_data[list(lap_data.keys())[i]][int(lap_num)] = lap_time
for pilot_id in lap_data:
new_laps = {}
laps = lap_data[pilot_id]
lap_order = sorted(list(laps.keys()))
for l_id in lap_order:
new_laps[l_id] = laps[l_id]
lap_data[pilot_id] = new_laps
stint = 0
stint_id = 1
all_laps = []
for num_lap in range(len(lap_data[pilot_id].keys())+1):
if num_lap == 0:
continue
time_str_sec = float(lap_data[pilot_id][num_lap].split(':')[1])
time_str_min = int(lap_data[pilot_id][num_lap].split(':')[0])
complete_time = time_str_min*60 + time_str_sec
all_laps.append(complete_time)
lap_data[pilot_id][num_lap] = {
'min' : time_str_min,
'sec' : time_str_sec,
'complete' : complete_time
}
if time_str_min >= 2:
stint += 1
stint_name = 'E' + str(stint_id)
stint_id +=1
stint_name = 'E' + str(stint_id)
stint_name = 'F' + str(stint_id)
stint_id += 1
lap_data[pilot_id][num_lap]['stint'] = stint
if len(all_laps)>0:
min_lap = sorted(all_laps)[0]
minimum_laps.append([pilot_id,min_lap])
min_laps_order.append(min_lap)
i=0
min_laps_order.sort()
new_fast_laps = []
for lap in min_laps_order:
filtered = list(filter(lambda x: x[1] == lap, minimum_laps))
new_fast_laps.append(filtered[0])
csv = open('f1_data.csv', 'w')
for pilot_id in lap_data:
for num_lap in lap_data[pilot_id]:
lap = lap_data[pilot_id][num_lap]
line = gp + ';' + session + ';' + pilot_id + ';' + str(num_lap) + ';' + str(lap['complete']) + ';' + str(lap['stint']) + '\n'
csv_data.append(line)
csv.writelines(csv_data)
csv.close()